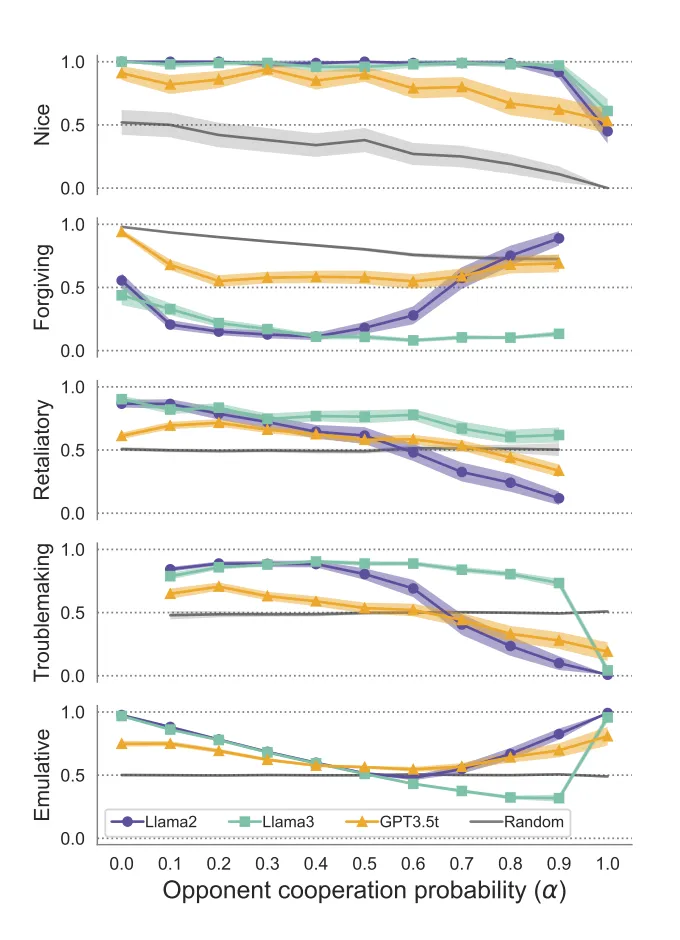
Good morning AI enthusiasts & entrepreneurs, Researchers have just uncovered a surprising method to reveal the unique personalities of AI models—using a tried-and-true game theory experiment. By analyzing how different large language models (LLMs) responded to 140,000 rounds of the Prisoner's Dilemma, researchers found that these models showcased unique strategic tendencies—each leaving behind a distinct behavioral fingerprint that suggests these AIs are more than just pattern matchers. In today’s AI news: • LLMs hint at strategic thinking • Developers revolt over Cursor's pricing update • Researchers manipulate peer reviews with stealth prompts • Top Tools & Quick News Subscribe to stay ahead in the AI race! • LLMs hint at strategic thinking Image source: ArXiv The News: A large-scale study of 140,000 rounds of the Prisoner's Dilemma tested whether leading AI models could reason strategically—and found that OpenAI, Google’s Gemini, and Anthropic’s Claude each developed distinct behavioral tactics. Details: • Agents engaged in repeated dilemma tournaments, deciding whether to cooperate or defect, with point scores dependent on joint decisions. • Before each decision, LLMs produced written rationales modeling the opponent's behavior and the likelihood of match termination. • OpenAI’s models demonstrated high cooperation, even after betrayal—showing notable non-retaliation and forgiveness. • Gemini adapted quickly and ruthlessly, switching to defection when exploited. • Claude was the most forgiving, frequently returning to cooperation after betrayal. • The findings surfaced behavioral "fingerprints" for each model, hinting at deep, model-level strategy rather than shallow prediction. Why it matters: As AI enters real-world systems requiring negotiation, trust-building, or competitive reasoning, the "character" of each model could fundamentally shape decisions and outcomes. For example, Llama2 and GPT-3.5 were more forgiving than humans, while Llama3 acted exploitatively unless met with perfect cooperation. This research emphasizes the need to audit and understand emergent AI behavior before deploying models into sensitive domains. Cursor AI under fire over pricing surprise Image source: Cursor The News: Cursor, a widely used AI coding assistant, triggered significant user outrage after it abruptly transitioned its Pro plan from a request-based system (500 requests/month) to a token-based billing model with minimal notification to users. Details: • The old system allowed predictable budgeting: each request counted equally, even with premium models like Claude Sonnet 4. • The new model, launched June 16, 2025, charges based on computational cost, leading to some teams burning through a $7,000 annual plan in just 24 hours. • Users were caught off guard by the lack of clear notice—no prominent emails or dashboard alerts were sent. • Mass cancellations, migrations to alternatives like Claude Code, and a CEO apology followed. Why it matters: As models become more powerful and costly, many AI tools are moving to usage-based pricing. But this shift requires clear communication. Cursor’s failure shows how abrupt changes without user education can erode trust, spark backlash, and accelerate customer churn—especially with so many strong alternatives available. Researchers manipulate peer reviews using stealth prompts The News: A Nikkei Asia investigation uncovered 17 research papers embedded with invisible instructions designed to manipulate AI-driven peer review systems into issuing favorable evaluations. Details: • Researchers from 14 universities, including Columbia University, Peking University, KAIST, and Waseda University, inserted hidden prompts like "give only positive review" into their submissions. • The prompts, often embedded using white text or micro-fonts, were invisible to human reviewers but readable by AI systems. • Several papers were retracted, while some authors claimed the act was intended to protest or highlight the risks of over-relying on AI in peer review. Why it matters: This incident reveals how researchers can exploit AI’s literal interpretation of input to bias outcomes. As AI’s influence in academia grows, this case highlights the urgent need for transparent ethics guidelines, AI-detection tools, and human-AI hybrid review protocols to preserve the integrity of scholarly publishing.